Конвейеры данных являются основой современного управления данными, обеспечивая бесшовную передачу информации от источника к назначению. Эти конвейеры играют ключевую роль в эффективной обработке, преобразовании и хранении данных для анализа. Поскольку компании стремятся к улучшению принятия решений и стратегическим инсайтам, значение конвейеров данных продолжает расти. В этом блоге мы подробно рассмотрим тонкости конвейеров данных, исследуем их определение, функции, компоненты и многочисленные преимущества, которые конвейеры данных предлагают в современном мире, ориентированном на данные.
Конвейер данных является основой любой организации, ориентированной на данные, обеспечивая плавный поток данных от источника до места, где они необходимы для анализа и принятия решений. Поскольку компании всё больше придают значение обоснованным решениям и стратегическим инсайтам, значение и использование конвейеров данных продолжает расширяться.

Конвейер данных — это система, которая автоматизирует извлечение, преобразование и загрузку (ETL) данных из различных источников в пункт назначения для анализа и использования. Она обеспечивает плавный и эффективный поток данных, делая их готовыми для запросов и получения аналитической информации.
Основная концепция конвейера данных
Конвейер данных включает в себя систематический поток данных через три основные стадии: сбор, обработка и хранение/анализ.
Сбор: Исходные данные собираются из различных источников, таких как базы данных, журналы, API или потоковые платформы. Данные могут быть структурированными, полуструктурированными или неструктурированными.
Обработка: Собранные данные очищаются, преобразуются и обогащаются, чтобы сделать их пригодными для анализа. Этот этап включает в себя задачи, такие как проверка данных, нормализация, агрегация и фильтрация.
Хранение/Анализ: Обработанные данные сохраняются в подходящем хранилище, таком как дата-центр, озеро данных или база данных. Затем они могут быть проанализированы, подвергнуты запросам и визуализированы для получения инсайтов и поддержки принятия решений.
Конвейеры данных могут работать в пакетном режиме или в реальном времени, в зависимости от требований конкретного случая использования. Они необходимы для того, чтобы организации могли эффективно управлять своими данными и использовать их для отчетности, аналитики, машинного обучения и других целей.
Исторический контекст конвейера данных
Конвейеры данных претерпели значительную эволюцию вместе с развитием технологий, превратившись из простых решений для перемещения данных в незаменимые компоненты, способствующие бизнес-трансформации. Вот краткий обзор их исторического контекста:
Раннее управление данными
В ранние дни вычислительной техники данные управлялись в основном с помощью простых файловых систем и баз данных. Перемещение и преобразование данных были в значительной степени ручными процессами, часто включающими пользовательские скрипты и разовые решения. Этот подход был трудоемким и подверженным ошибкам, что ограничивало возможности масштабирования и обработки растущих объемов данных.
Появление процессов ETL
Когда бизнес начал осознавать ценность данных для принятия решений, возникла потребность в более структурированных и автоматизированных процессах управления данными. Это привело к разработке инструментов ETL (извлечение, преобразование, загрузка) в 1970-х и 1980-х годах. Процессы ETL позволяют организациям систематически извлекать данные из различных источников, преобразовывать их в единый формат и загружать в центральное хранилище данных, такое как дата-центр. Это был значительный шаг вперед в управлении данными, обеспечивающий более надежную и масштабируемую обработку данных.
Рост хранения данных
В 1990-х и начале 2000-х годов хранение данных стало ключевым компонентом стратегии управления данными в предприятиях. Компании, такие как Teradata, IBM и Oracle, разработали сложные решения для дата-центров, чтобы поддерживать хранение и анализ данных в крупном масштабе. Распространение хранилищ данных еще больше подчеркнуло важность эффективных конвейеров данных, которые обеспечивают эти хранилища чистыми, структурированными данными.
Революция больших данных
В середине 2000-х годов произошла революция в области больших данных, вызванная взрывным ростом данных, генерируемых веб-приложениями, социальными сетями и устройствами IoT. Фреймворки, такие как Hadoop, а позже Spark, произвели революцию в обработке данных, позволив использовать распределенные вычисления и обрабатывать огромные наборы данных. Конвейеры данных должны были эволюционировать, чтобы приспособиться к этим новым технологиям, поддерживая обработку данных в реальном времени и более сложные преобразования.
Современные конвейеры данных
Сегодня конвейеры данных являются неотъемлемой частью современной экосистемы данных. Они поддерживают широкий спектр источников данных, включая облачные сервисы, данные в реальном времени и различные API. Современные конвейеры данных разработаны с учетом высокой масштабируемости, автоматизации и гибкости, используя облачные платформы, такие как AWS, Google Cloud и Azure. Инструменты, такие как Apache Kafka, Apache NiFi и облачные ETL-сервисы, упростили создание и управление надежными конвейерами данных.
В заключение, эволюция конвейеров данных отражает более широкие тенденции в управлении данными и технологиях, переходя от ручных процессов к сложным автоматизированным системам, способным поддерживать сложные потребности данных современных организаций.
Конвейер данных предназначен для обеспечения плавного и эффективного перемещения данных из различных источников к пункту назначения, подготавливая их к анализу и использованию. Вот его основные функции:
Сбор данных:
• Сбор: Сбор исходных данных из множества источников, таких как базы данных, API, журналы и потоковые платформы. Интеграция: Объединение данных из различных источников в единую, согласованную систему для дальнейшей обработки.
• Обработка и преобразование данных: Очищение: Удаление ошибок, дубликатов и несоответствий для обеспечения качества данных. Проверка: Удостоверение в том, что данные соответствуют заранее определенным стандартам и критериям. Преобразование: Преобразование данных в желаемый формат или структуру, что может включать нормализацию, агрегацию или обогащение данных. Фильтрация: Исключение неактуальных или ненужных данных для сосредоточения на полезной информации.
Хранение данных:
• Загрузка: Перемещение обработанных данных в системы хранения, такие как дата-центры, озера данных или базы данных.
• Оптимизация: Хранение данных таким образом, чтобы оптимизировать производительность запросов и доступность.
Оркестрация данных и управление рабочими процессами:
• Планирование: Автоматизация времени и последовательности задач конвейера данных.
• Мониторинг: Непрерывное отслеживание производительности конвейера для выявления проблем и обеспечения его бесперебойной работы.
• Обработка ошибок: Выявление и устранение ошибок или сбоев в потоке данных для поддержания целостности данных и надежности конвейера.
Обработка в реальном времени:
• Обработка потоковых данных: Обработка данных по мере их поступления в реальном времени, что позволяет своевременно проводить анализ и принимать решения.
• Обработка событий: Быстрая реакция на конкретные события или триггеры в потоке данных.
Доставка данных и визуализация
• Экспорт данных: Предоставление обработанных данных для последующих систем, приложений или пользователей.
• Визуализация: Создание панелей мониторинга, отчетов и визуальных представлений для того, чтобы инсайты были легко доступными и пригодными для принятия действий.
В общем, ключевые функции конвейера данных охватывают весь жизненный цикл данных от их первоначального сбора до конечного использования, обеспечивая качество, эффективность и надежность данных на протяжении всего процесса.
Источники данных конвейеров данных
В области конвейеров данных типы источников данных, которые служат исходными точками информации, разнообразны и различны, каждый из которых вносит уникальные инсайты в общий набор данных. Понимание этих источников имеет решающее значение для организаций, стремящихся к комплексным аналитическим возможностям.
• Внутренние источники: Информация, генерируемая внутри организации, такая как записи о продажах, базы данных клиентов или операционные метрики.
• Внешние источники: Данные, полученные от внешних организаций, такие как отчеты по рыночным исследованиям, ленты социальных сетей или публичные наборы данных.
• Источники потоковых данных: Реальные данные в реальном времени, которые предоставляют мгновенные обновления по различным метрикам, позволяя оперативно принимать решения.
• Устаревшие системы: Исторические базы данных или архивы, хранящие прошлую информацию, критически важную для анализа тенденций и прогнозирования.
Изучите примеры этих источников данных в действии:
• Системы управления взаимоотношениями с клиентами (CRM): Эти платформы хранят ценные данные о клиентах, включая контактную информацию, историю покупок и предпочтения.
• Платформы социальных сетей: Богатые источники пользовательского контента и показателей вовлеченности, которые дают представление о поведении и тенденциях потребителей.
• IoT-устройства: Подключенные устройства генерируют огромные объемы данных в режиме реального времени о производительности, характере использования и условиях окружающей среды.
• Отчеты об исследованиях рынка: Внешние исследования предоставляют отраслевые данные о тенденциях рынка, предпочтениях потребителей и конкурентной среде.
В сложной структуре конвейера данных процесс ETL (Extract, Transform, Load) играет ключевую роль в преобразовании необработанных данных в полезные сведения. Этот многогранный подход предполагает извлечение необходимой информации из различных источников, преобразование ее в стандартный формат и загрузку в хранилище для дальнейшего анализа.
• Извлечение: начальный этап включает в себя получение необработанных данных из различных источников, таких как базы данных, API или файлы.
• Преобразование: После этого извлеченные данные подвергаются процессу преобразования, чтобы обеспечить согласованность и совместимость различных наборов данных.
• Загрузка: Наконец, уточненные данные загружаются в специальные хранилища для хранения и последующего извлечения.
Когда речь идет о процессе ETL, компании часто сталкиваются с проблемой ручных процессов, отнимающих много времени. Значительное время и усилия тратятся на ручное извлечение, преобразование и загрузку данных (ETL), что делает эти процессы подверженными ошибкам и неэффективности.
Использование профессиональной платформы интеграции данных, такой как FineDataLink, может помочь компаниям преодолеть эти вызовы ETL. FineDataLink синхронизирует данные между несколькими таблицами в реальном времени с минимальной задержкой, обычно измеряемой в миллисекундах. Это делает его идеальным для миграции баз данных и резервного копирования, а также для построения реальных хранилищ данных.
Одна из его основных функций — своевременное вычисление и синхронизация данных, которые могут использоваться для предварительной обработки данных и в качестве инструмента ETL для построения хранилищ данных. Кроме того, API-интерфейс можно разработать и запустить всего за пять минут без написания кода. Эта возможность особенно полезна для обмена данными между различными системами, особенно SaaS-приложениями.
Преобразуйте свой опыт интеграции данных! Нажмите на баннер ниже, чтобы бесплатно попробовать FineDataLink и увидеть, насколько бесшовным может быть управление данными!

Кроме того, валидация данных служит критической точкой контроля в конвейере для проверки точности и целостности обработанной информации перед ее хранением или анализом. Реализуя протоколы и проверки в ключевых этапах обработки, организации могут поддерживать высокое качество данных, необходимое для принятия обоснованных решений.
В контексте конвейеров данных эффективные механизмы хранения имеют первостепенное значение для защиты обработанной информации, одновременно обеспечивая доступность для аналитических целей. Два основных решения для хранения, которые часто применяются, это озера данных и хранилища данных, каждое из которых предлагает различные преимущества в зависимости от потребностей организации.
Озера данных
Озера данных представляют собой огромные резервуары, способные хранить структурированные и неструктурированные данные в их естественном формате без предварительной обработки. Такая гибкость позволяет организациям сохранять большие объемы необработанной информации для последующего анализа без заранее определенных схем или структур.
Хранилища данных
С другой стороны, хранилища данных оптимизированы для эффективного запроса и анализа структурированных массивов данных. Они организуют информацию в таблицы с определенными связями и схемами, что делает сложные запросы более эффективными. Стратегическое использование этих вариантов хранения данных в своих конвейерах позволяет организациям эффективно управлять своими информационными активами и обеспечивать беспрепятственный доступ к ценным сведениям, когда это наиболее необходимо.
В области управления данными конвейеры данных выделяются как важные инструменты, которые значительно повышают эффективность и точность данных. Оптимизируя управление данными, эти конвейеры автоматизируют повторяющиеся задачи, уменьшая человеческие ошибки и обеспечивая постоянное качество данных. Организации могут принимать более быстрые и обоснованные решения, используя возможности конвейеров данных для эффективной обработки больших объемов структурированной и неструктурированной информации. С развитием современных технологий конвейеры данных бесшовно интегрируются с системами обработки в реальном времени, облачными решениями, интеграцией машинного обучения и инструментами автоматизации.
Конвейеры данных эффективно оптимизируют ресурсы.
• Снижают объем ручного труда и упрощают процессы.
• Минимизация избыточности данных приводит к экономии затрат.
• Производительность улучшается за счет эффективной обработки данных.
• Поддержка обработки в режиме реального времени для получения мгновенных выводов.
• Гибкость при работе с различными типами данных для улучшения интеграции.
• Обеспечьте гибкость операций, адаптируясь к изменениям в источниках и форматах.
Решения для конвейерной обработки данных уделяют первостепенное внимание таким важным аспектам, как управление, безопасность, целостность, соответствие требованиям и оркестровка на протяжении всего жизненного цикла данных. Автоматизируя рабочие процессы и оптимизируя процессы разработки, эти решения повышают операционную эффективность, сокращая ручные операции. Упор на повышение эффективности позволяет организациям поддерживать постоянный уровень производительности и эффективно оптимизировать распределение ресурсов.
• Обеспечить последовательность в обработке различных наборов данных.
• Поддерживать высокие стандарты качества во всей обработанной информации.
• Повышать надежность через надежные меры безопасности.
• Соблюдать отраслевые стандарты для безопасной обработки данных.
Конвейеры данных предлагают высокий уровень функциональности, поддерживая возможности обработки в реальном времени. Эта функция позволяет организациям получать немедленные инсайты из входящих потоков данных для оперативного принятия решений. Гибкость, предоставляемая этими конвейерами, позволяет бесшовное масштабирование для эффективного удовлетворения развивающихся бизнес-потребностей.
Используя функции обработки данных в режиме реального времени, организации могут оперативно извлекать ценные сведения из поступающих наборов данных, что позволяет оперативно реагировать на изменение динамики рынка и поведения потребителей.
Применение обработки данных в реальном времени выходит за рамки простой аналитики, позволяя компаниям реализовывать динамические стратегии, основанные на актуальной информации. Используя скорость и адаптивность современных решений для обработки данных, организации могут опережать конкурентов, заблаговременно предвидеть тенденции и быстро использовать возникающие возможности.
Определение требований
Чтобы приступить к внедрению конвейера данных, организации должны сначала тщательно определить свои требования. Это включает в себя оценку объема и разнообразия данных, которые необходимо обрабатывать, понимание конкретных бизнес-целей, обуславливающих необходимость создания конвейера данных, и определение ключевых показателей эффективности (KPIs) для оценки его успешности. Проведя всесторонний анализ этих факторов, компании смогут настроить конвейер обработки данных таким образом, чтобы он полностью соответствовал их операционным и аналитическим потребностям.
Выбор инструментов
Выбор правильных инструментов критически важен для успешной реализации конвейера данных. FineDataLink выделяется как универсальное решение, позволяющее пользователям эффективно определять и планировать рабочие процессы. Его поддержка динамического создания конвейеров и параллельной обработки задач делает его идеальным выбором для организаций, стремящихся к масштабируемости и гибкости в своих операциях по обработке данных. Кроме того, FineDataLink служит надежной платформой интеграции данных, создавая прочные конвейеры данных и обеспечивая бесперебойный поток данных от источника к назначению.
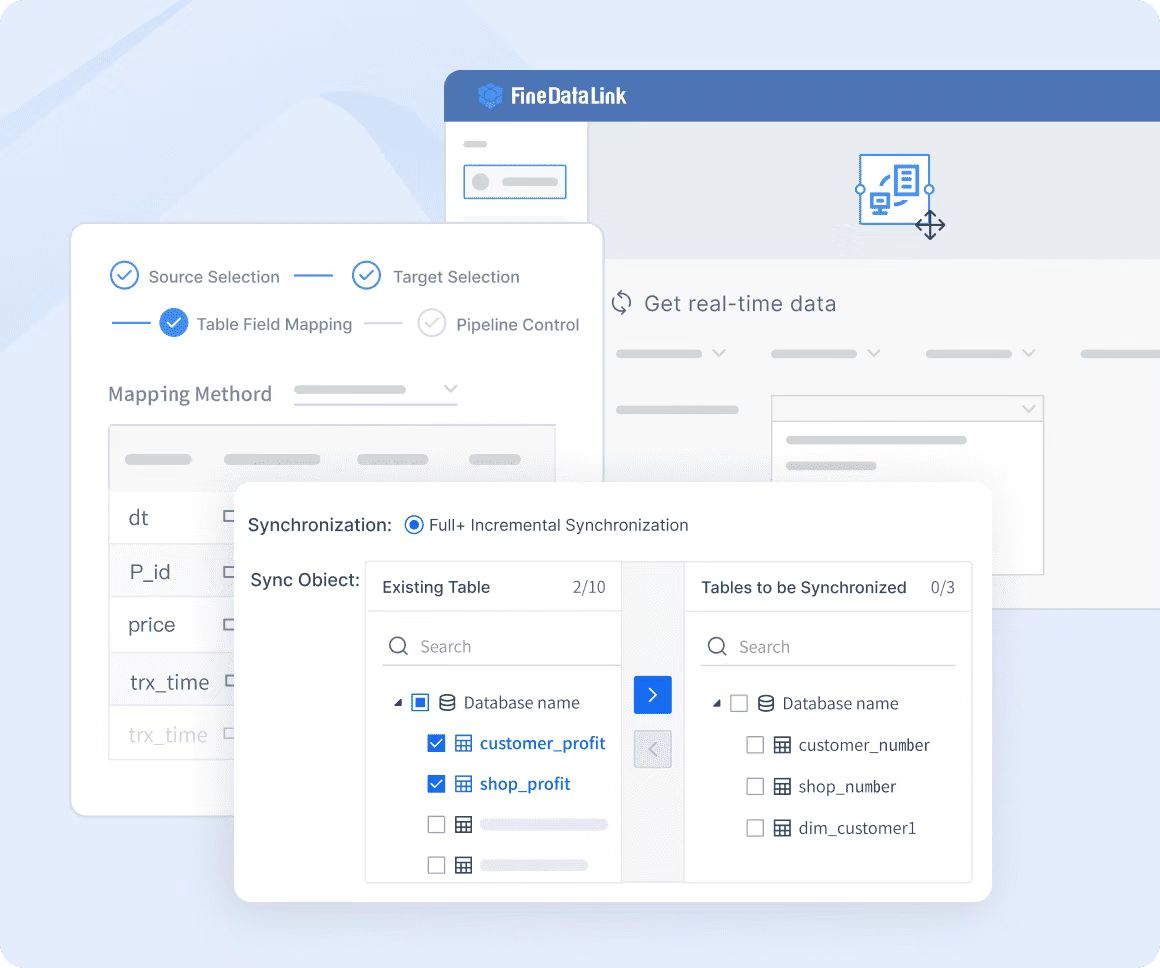
Эффективное строительство хранилищ данных
Платформа с низким кодом упрощает миграцию данных предприятия в хранилище данных, снижая вычислительные нагрузки.
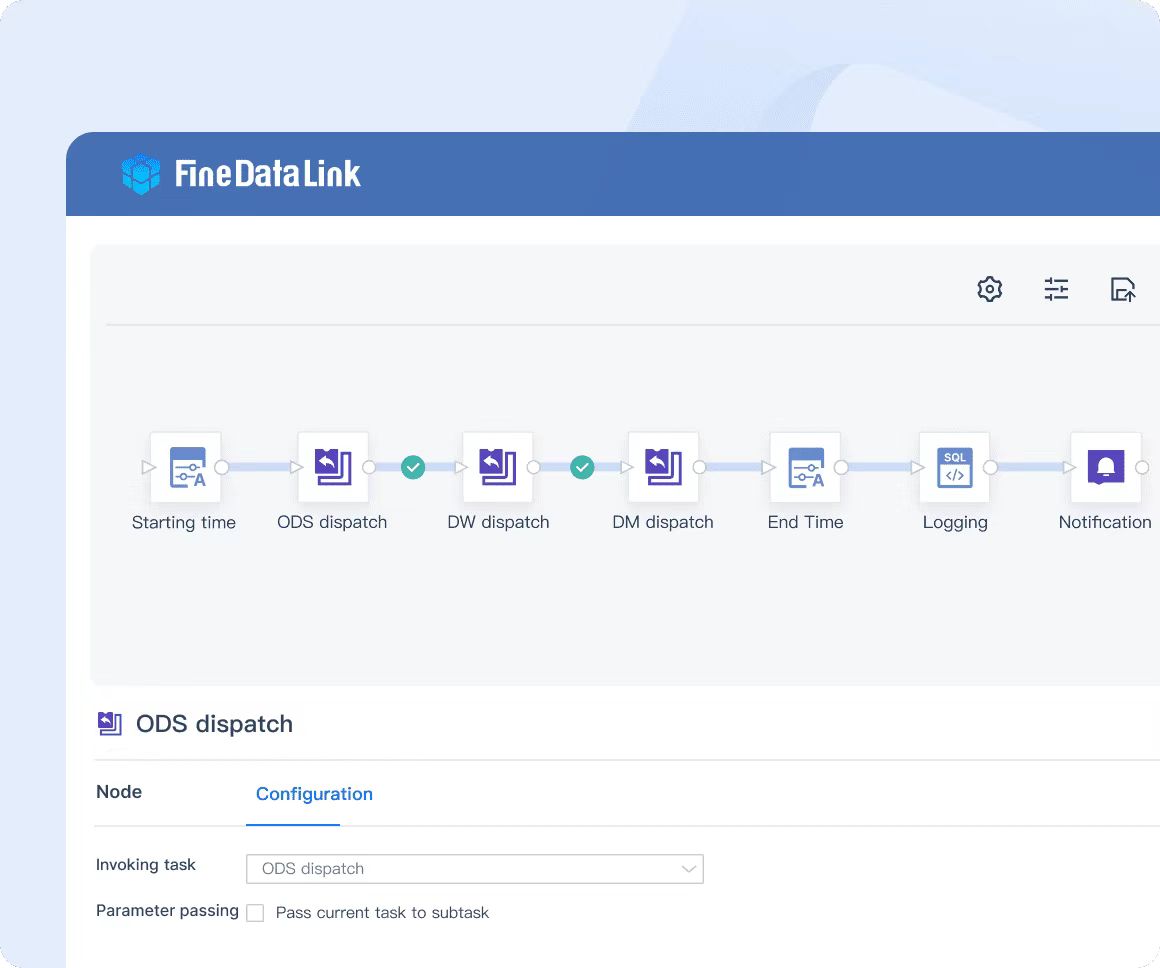
Интеграция данных в реальном времени
Используйте конвейеры данных и технологии мониторинга журналов для эффективного решения проблем, связанных с большими объемами данных и задержками.
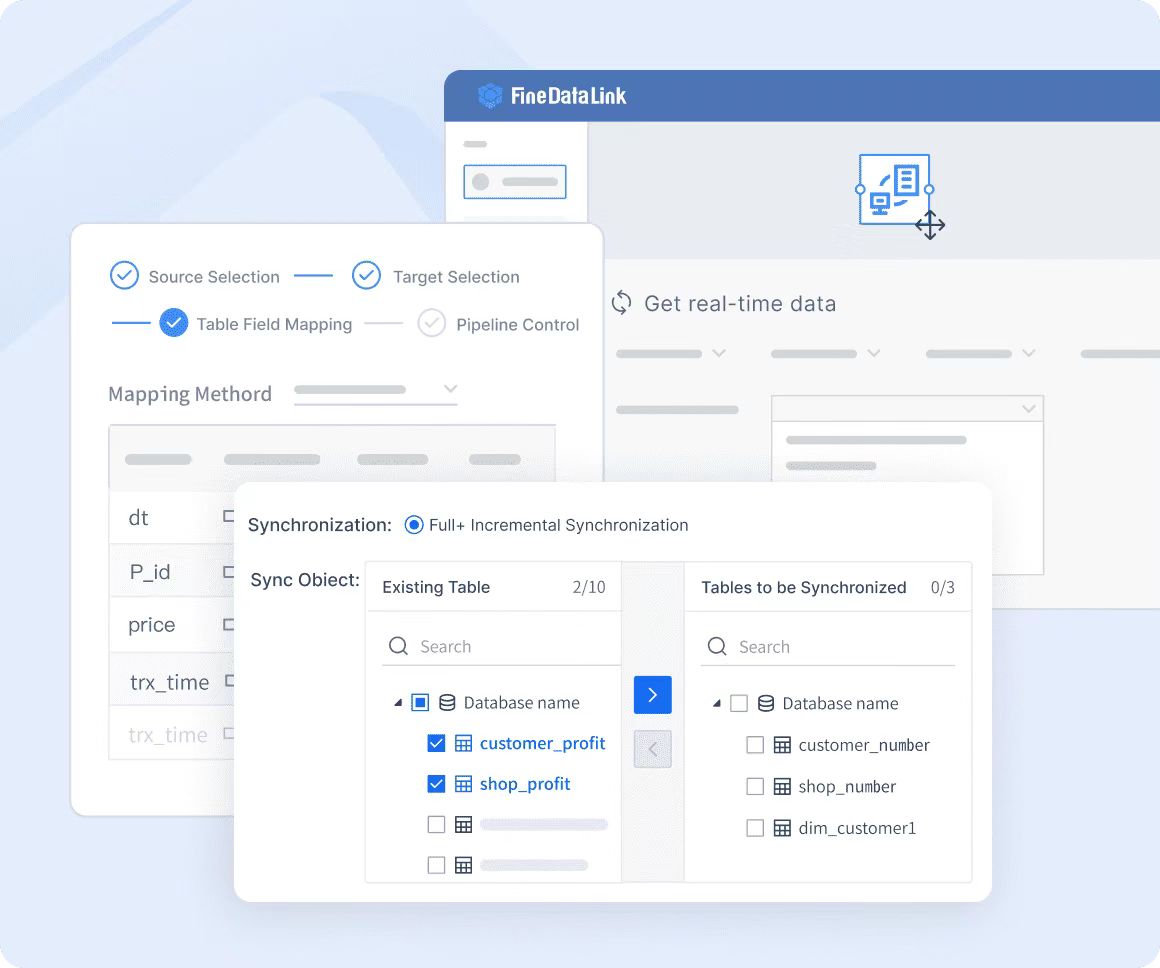
Интеграция приложений и API
Используйте возможности учета данных API, чтобы сократить время разработки интерфейса с 2 дней до 5 минут.
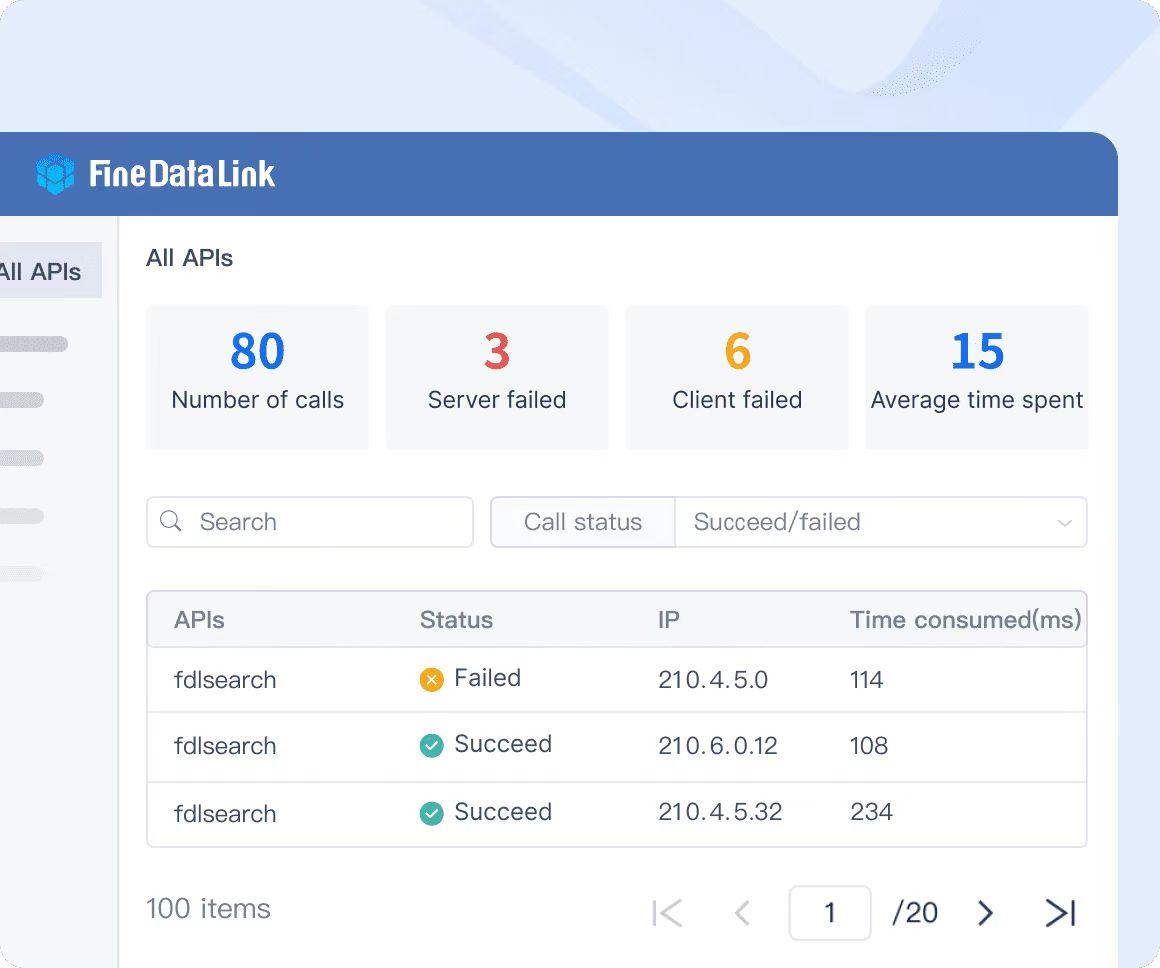
Улучшенная связь данных
Обеспечьте бесшовную передачу данных между приложениями SaaS и в различных облачных средах.
Как современное и масштабируемое решение для конвейеров данных, FineDataLink решает задачи интеграции данных, качества данных и аналитики данных через три основные функции: синхронизацию данных в реальном времени, ETL/ELT и API.
Построение конвейера
Фаза разработки обозначает практическую реализацию запланированной архитектуры конвейера данных. Использование таких инструментов, как FineDataLink, позволяет организациям создавать сложные конвейеры, соответствующие их уникальным требованиям. Демократизируя аналитику данных с помощью удобных интерфейсов и настраиваемых рабочих процессов, компании могут эффективно оптимизировать свои операции по обработке данных. Возможность определения операторов и исполнителей внутри этих конвейеров позволяет пользователям легко управлять сложными задачами.
Тестирование
Тщательное тестирование имеет решающее значение для проверки функциональности и надежности вновь разработанного конвейера данных. Инструменты, такие как Shipyard, предоставляют комплексные возможности для тестирования, которые автоматизируют процесс проверки, обеспечивая бесперебойное функционирование процессов извлечения, преобразования и загрузки данных (ETL). Моделируя реальные сценарии и крайние случаи во время тестирования, организации могут рано выявить потенциальные узкие места или проблемы, снижая риски до развертывания конвейера в производственных средах.
Мониторинг
Непрерывный мониторинг критически важен для поддержания оптимальной производительности конвейера данных после его реализации. Платформы, такие как FineDataLink, предлагают мощные инструменты мониторинга, которые отслеживают ключевые показатели эффективности (KPI), обнаруживают аномалии и предоставляют информацию в реальном времени о эффективности конвейера. Проактивно мониторя использование ресурсов, скорость обработки данных и журналы ошибок, организации могут быстро решать возникающие проблемы, обеспечивая бесперебойный поток данных в конвейере.
Устранение неполадок
Неизбежно, что во время работы конвейера данных могут возникнуть проблемы, требующие мер по устранению неполадок. Решения, такие как FineDataLink, упрощают процесс устранения неполадок, предлагая интуитивно понятные интерфейсы для быстрого выявления и решения проблем. Эти инструменты повышают операционную эффективность, сводя к минимуму время простоя, связанное с отладкой, при этом поддерживая стабильные стандарты качества данных на всех этапах обработки.
Придерживаясь передовых методов планирования, разработки, обслуживания, мониторинга и устранения неполадок, организации могут оптимизировать использование облачных инструментов для автоматизации критических задач, связанных с эффективным сбором, консолидацией, преобразованием и загрузкой данных в целевые системы, такие как хранилища данных или озера данных.
Эти инструменты не только ускоряют скорость обработки, но и упрощают настройку рабочих процессов, делая их доступными даже для пользователей без технической подготовки, которые ищут решения для быстрого развертывания аналитики. Реальные данные конвейеров ещё больше повышают возможности организаций, позволяя быстро захватывать, анализировать и принимать меры по входящим данным, что даёт бизнесу своевременные инсайты для персонализированных услуг, рекомендаций, обнаружения мошенничества и идентификации аномалий.
Такие технологии, как FineDataLink, Apache Flink и Google Cloud Dataflow, играют ключевую роль в поддержке платформ для обработки данных в реальном времени, которые стимулируют постоянные инновации в современной аналитике.
Конвейеры данных являются краеугольным камнем современного управления данными, способствуя успеху бизнеса, превращая необработанные наборы данных в ценные инсайты. Организации используют конвейеры данных для автоматизации и масштабирования повторяющихся задач в потоке данных, что необходимо для своевременного и обоснованного принятия решений в условиях динамичного делового мира. Эффективно используя свои данные через эти конвейеры, компании могут получить конкурентное преимущество, отличиться от конкурентов и оставаться впереди в эпоху больших данных. Непрерывное развитие конвейеров данных имеет решающее значение для организаций, стремящихся к возможностям аналитики в реальном времени, чтобы оперативно и эффективно извлекать практическую информацию.
В заключение, соблюдая передовые практики выбора и внедрения решений для конвейеров данных, компании могут эффективно использовать силу этих преобразующих инструментов для удовлетворения своих постоянно меняющихся потребностей в данных. Учитывая все эти факторы, FineDataLink может стать вашим лучшим выбором.
Нажмите на баннер ниже, чтобы попробовать FineDataLink бесплатно и дайте вашей компании возможность превратить данные в продуктивность!

Автор
Howard
Инженер по управлению данными и эксперт по исследованию данных в компании FanRuan.
Похожие статьи



