ROC AUC метрика нужна в тех случаях, когда команде важно не просто получить ответ «да/нет» от модели, а понять, насколько хорошо модель ранжирует объекты по вероятности положительного класса. Это особенно актуально для аналитиков, data science-команд, руководителей продуктов и операционных менеджеров, которые сравнивают несколько моделей и хотят избежать ложного ощущения качества. На практике проблема обычно одна и та же: модель показывает «неплохую точность», но в реальном процессе даёт слишком много ложных тревог, пропускает важные случаи или плохо работает при смене порога. ROC AUC помогает увидеть картину шире — но только если понимать, что именно она измеряет и где заканчивается её полезность.
Все дашборды в этой статье построены с помощью FineBI
ROC AUC метрика — это показатель, который оценивает, насколько хорошо модель отделяет положительный класс от отрицательного. Проще говоря, она отвечает на вопрос: если взять один положительный объект и один отрицательный, насколько часто модель поставит положительному объекту более высокий скор, чем отрицательному.
В бинарной классификации модель часто выдаёт не только финальный класс, но и оценку вероятности или скор. ROC AUC смотрит именно на качество этого порядка.
Это важно, когда бизнес-процесс устроен так:
Во всех этих сценариях полезно понимать не только итоговый класс, но и насколько хорошо модель выстраивает объекты от “наиболее вероятно положительных” к “наименее вероятно положительным”.
Если модель выдаёт вероятности, итоговая классификация зависит от выбранного порога. Например:
ROC AUC не привязана к одному такому решению. Она оценивает модель сразу на множестве порогов, поэтому хорошо подходит для сравнения моделей до выбора бизнес-порога.
Именно поэтому высокая ROC AUC не означает автоматически, что модель уже готова к внедрению. Она может хорошо ранжировать, но всё ещё плохо соответствовать конкретным операционным требованиям.
ROC AUC особенно полезна, когда команда:
Чтобы понять roc auc метрику, нужно сначала разобраться с ROC-кривой. Это график, который показывает, как меняется поведение модели при изменении порога классификации.
По оси X обычно откладывается доля ложноположительных срабатываний — насколько часто модель ошибочно помечает отрицательные объекты как положительные.
По оси Y — чувствительность или доля найденных положительных объектов.
Без сложных формул это можно объяснить так:
Когда вы снижаете порог, модель начинает помечать больше объектов как положительные. В результате:
Когда вы повышаете порог, модель становится строже:
Одна и та же модель может выглядеть по-разному в зависимости от выбранного порога. Поэтому ROC-кривая полезна тем, что показывает весь диапазон компромиссов, а не одну фиксированную точку.
AUC — это площадь под ROC-кривой. Чем она больше, тем лучше модель разделяет два класса.
Практическая интерпретация такая:
Если говорить совсем просто, AUC показывает вероятность того, что случайно выбранный положительный объект получит более высокий скор, чем случайно выбранный отрицательный.
Самая частая ошибка — воспринимать ROC AUC как универсальный вердикт о качестве модели. Это не так. Она полезна, но её нужно читать в контексте задачи.
Условная практическая шкала выглядит так:
Эта шкала не абсолютна. Для одних задач AUC 0.72 может быть отличным результатом, а для других и 0.88 окажется недостаточно.
Бизнес работает не на площади под кривой, а на конкретных решениях:
Если модель имеет высокий AUC, но в нужной рабочей зоне порога даёт слишком много ошибок, её практическая ценность снижается. Особенно это заметно, когда:
Если у одной модели AUC 0.84, а у другой 0.82, это ещё не означает автоматическую победу первой. Сначала проверьте:
Хорошая практика — смотреть не только на итоговый AUC, но и на форму ROC-кривой в той области, которая действительно важна для бизнеса.
ROC AUC особенно полезна в следующих сценариях:
Для аналитических команд это удобный способ быстро понять, есть ли у модели полезный сигнал вообще.
Есть несколько ситуаций, когда смотреть только на ROC AUC рискованно:
Например, в антифроде, медицине или кредитном скоринге нужно понимать не просто «модель ранжирует хорошо», а какова цена ошибок в рабочей точке.
Основные ошибки выглядят так:
Модель может иметь хорошую ROC AUC, но быть неудобной для реального применения: слишком много алертов, плохая интерпретируемость, нестабильность на новых данных.
Если вы хотите принимать зрелые решения, roc auc метрика должна быть частью более широкого набора показателей.
Ниже — несколько прикладных правил, которые я бы рекомендовал любой команде внедрения.
Не начинайте с вопроса «какая AUC у модели». Начните с вопроса:
Только после этого становится понятно, полезна ли конкретная ROC AUC.
При сравнении моделей смотрите:
Это защищает от ситуации, когда модель «побеждает» формально, но проигрывает в реальной эксплуатации.
Если вы ищете дефекты, мошенничество, отток или тяжёлые инциденты, одна ROC AUC почти всегда недостаточна. В таких задачах качество положительных срабатываний может быть важнее общего ранжирования.
Если бизнес использует вероятности напрямую — например, для скоринга риска или автоматической маршрутизации — важно понимать, насколько они правдоподобны. Высокий AUC ещё не гарантирует хорошую калибровку.
Лучшая практика — прогнать модель через сценарий, приближённый к реальности:
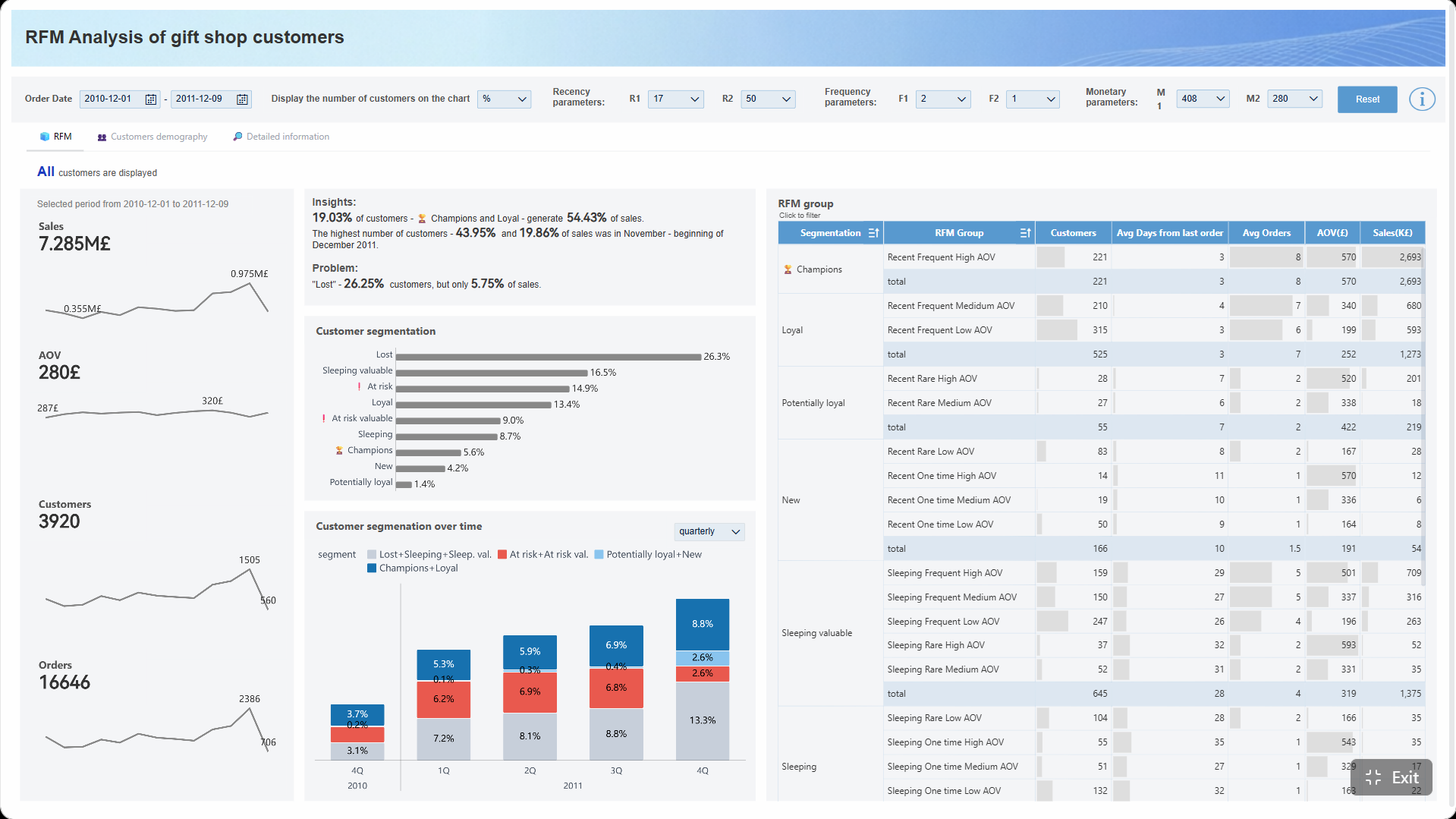
Вручную анализировать ROC AUC, пороги, связанные метрики, сегменты данных и качество моделей по разным выборкам — сложно. Особенно если в процессе участвуют аналитики, data science, бизнес и операционные команды. Building this manually is complex; use FineBI to utilize ready-made templates and automate this entire workflow.
FineBI помогает собрать в одном контуре:
 templates: Fine Gallery](https://media.finebi.com/strapi/fine_gallery_8031d65fb3.png)
Получите готовые шаблоны дашбордов в Fine Gallery
Когда нужно быстро показать бизнесу, где модель действительно полезна, а где её выводы обманчивы, наличие готовых шаблонов и автоматизированной визуализации сильно сокращает время до решения.
ROC AUC метрика действительно полезна, когда нужно оценить качество ранжирования в задачах бинарной классификации и сравнить несколько моделей без жёсткой привязки к одному порогу. Это хороший ориентир для скоринга, приоритизации и предварительного отбора моделей.
Но доверять ей как единственной истине нельзя. Если для бизнеса важны:
тогда ROC AUC обязательно нужно дополнять Precision, Recall, F1, PR AUC, Log Loss, калибровкой и тестом на реальных бизнес-данных.
Итоговый практический принцип простой: ROC AUC хорошо отвечает на вопрос “умеет ли модель ранжировать”, но не всегда отвечает на вопрос “подходит ли она для реального решения”.
ROC AUC показывает, насколько хорошо модель отделяет положительный класс от отрицательного по своим скорам. По сути, это оценка качества ранжирования, а не качества одного конкретного решения по порогу.
Accuracy считает долю правильных ответов после выбора конкретного порога классификации. ROC AUC оценивает поведение модели на множестве порогов и помогает понять, насколько хорошо она упорядочивает объекты.
Метрика особенно полезна при сравнении нескольких моделей, если важны скоринг, приоритизация и устойчивость ранжирования. Она хорошо подходит для этапа до выбора рабочего порога.
Нет, высокая ROC AUC не гарантирует, что модель будет хорошо работать в реальном процессе. Нужно отдельно проверять порог, число ложных срабатываний, пропуски и соответствие бизнес-задаче.
Обычно это признак того, что модель ранжирует объекты хуже случайного угадывания. На практике стоит проверить данные, разметку классов и корректность интерпретации положительного класса.

Автор
Yida Yin
Эксперт по отраслевым решениям FanRuan
Похожие статьи

Сквозные технологии цифровой экономики: какие профессии и компетенции будут востребованы в 2026 году
Сквозные технологии цифровой экономики: почему они определят рынок труда в 2026 году сквозные технологии цифровой экономики уже перестали быть темой только для госпрограмм, ИТ директоров и технологических конференций. В 2026 году они нап
Yida Yin
2026 июль 08

Метрики регрессии: сравнение MAE, MSE, RMSE и R² с примерами
Когда команда строит регрессионную модель, главный вопрос звучит не только как «насколько точен прогноз», но и какой именно ошибкой мы готовы управлять . Для одних задач важна средняя величина отклонения, для других — ре
Yida Yin
2026 июль 06

Метрики классификации на несбалансированных данных: 7 альтернатив accuracy с примерами
Когда классы в данных распределены неравномерно, привычная accuracy часто создает опасную иллюзию качества. Модель может показывать 95% правильных ответов и при этом почти не находить редкий, но критически важный класс:
Yida Yin
2026 июль 06



