Когда команда внедряет модель классификации в антифрод, скоринг лидов, прогноз оттока или медицинский триаж, ошибка в выборе метрики быстро превращается в бизнес-проблему. Модель может показывать «красивую» accuracy, но проваливаться там, где для бизнеса критично не пропускать важные события и не засорять процесс ложными срабатываниями. Именно поэтому запрос «f1 score что это» так часто возникает у ML-инженеров, аналитиков данных, product- и операционных руководителей: F1-score помогает оценить, насколько модель одновременно точна и полезна в реальной работе.
«Все дашборды в этой статье построены с помощью [FineBI]»
Если объяснять совсем просто, F1-score — это метрика качества классификации, которая показывает баланс между precision и recall. То есть она отвечает не только на вопрос «сколько модель угадала», но и на вопрос «насколько полезны эти предсказания на практике».
Для бизнеса это особенно важно в сценариях, где цена ошибки несимметрична. Например:
F1-score объединяет две ключевые характеристики модели:
Если одна из этих величин сильно проседает, F1-score тоже падает. В этом его практическая ценность: метрика не даёт спрятать слабость модели за одним сильным показателем.
Accuracy выглядит удобно: это доля правильных ответов. Но в реальных задачах она часто вводит в заблуждение.
Представьте задачу выявления мошенничества, где 98% операций — нормальные. Модель может просто всегда говорить «всё нормально» и получить очень высокую accuracy. Но пользы от неё не будет: она не ловит мошенников вообще.
В таких сценариях F1-score информативнее, потому что фокусируется на качестве распознавания значимого класса, а не на общем проценте угадываний.
F1-score особенно полезен там, где:
Типичные примеры:
Ниже — базовый набор показателей, который стоит отслеживать вместе с F1-score:
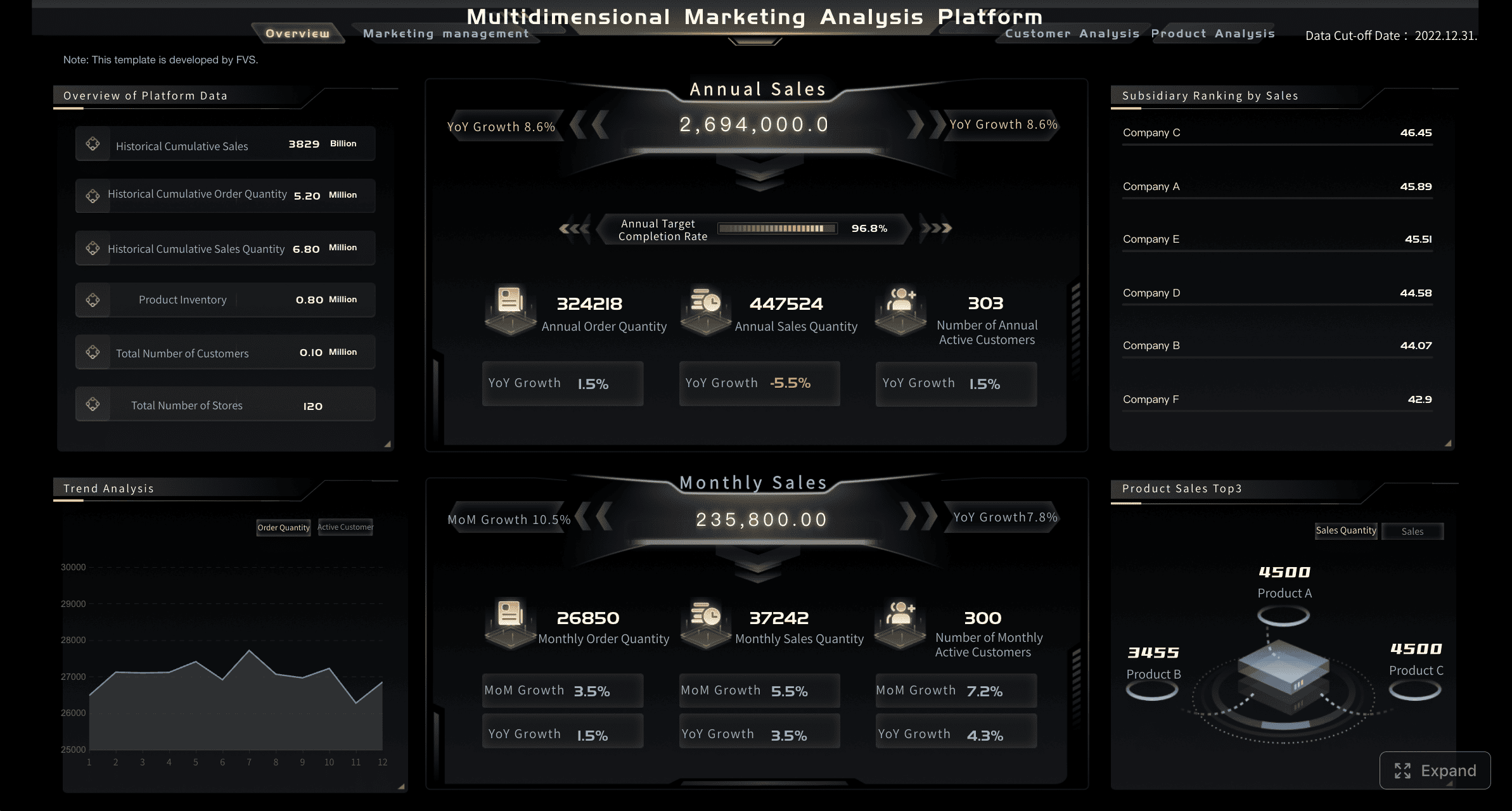
На уровне здравого смысла F1-score показывает, умеет ли модель одновременно:
Если один из этих аспектов страдает, итоговая метрика не будет высокой.
Precision и recall почти всегда находятся в напряжении друг с другом. Усиливая один показатель, вы нередко ухудшаете другой.
Представим модель, которая ищет подозрительные транзакции.
Если повысить строгость модели, можно получить высокий precision: ложных тревог станет меньше. Но часть реальных мошеннических операций начнёт ускользать, и recall упадёт.
Если, наоборот, сделать модель более «подозрительной», recall вырастет, но вместе с ним вырастет число ложных срабатываний, а precision снизится.
F1-score полезен именно потому, что штрафует перекос. Нельзя получить действительно высокий F1-score, если:
Это делает метрику хорошим ориентиром для команд, которым нужна рабочая, а не просто красивая модель.
Высокий F1-score особенно важен, когда модель влияет на деньги, риск, качество сервиса или нагрузку на сотрудников.
Один и тот же F1-score может означать разную ценность в зависимости от контекста.
Например:
Поэтому смотреть на F1-score нужно не в вакууме, а в связке с процессом и стоимостью ошибок.
Нет. Высокий F1-score не означает, что модель идеальна.
Он не показывает напрямую:
Именно поэтому зрелые команды всегда смотрят на набор метрик, а не на одну цифру.
F1-score — одна из самых практичных метрик для прикладного ML, особенно в сценариях бинарной классификации.
Чаще всего F1-score используют там, где есть два исхода: «да/нет», «риск/не риск», «мошенничество/норма», «уйдёт/не уйдёт».
Вот типовые сценарии, где F1-score особенно уместен:
В прикладных задачах положительный класс часто редкий:
В такой ситуации accuracy почти всегда выглядит лучше, чем реальное качество модели. F1-score помогает сместить фокус на качество распознавания редкого, но ценного класса.
Несмотря на полезность, F1-score — не универсальный ответ на все вопросы.
Дополнительно стоит использовать:
F1-score может скрыть проблемы, если:
Поэтому для руководителя или владельца продукта правильный вопрос звучит не «какой у нас F1-score?», а «что стоит за этим F1-score и как он влияет на процесс?».
Ниже — 10 практических способов, которые чаще всего действительно помогают поднять F1-score. Это не теоретический список, а типовой набор действий, который используют команды в production-среде.
Качество модели почти всегда ограничено качеством данных. Если входной набор шумный, F1-score будет упираться в потолок.
Начните с базовой гигиены данных:
На практике именно ошибки в лейблах часто убивают recall или precision сильнее, чем выбор алгоритма.
Проверьте:
Иногда удаление нескольких слабых или шумных признаков даёт более стабильный рост F1-score, чем сложный тюнинг модели.
Если один класс сильно преобладает, модель может научиться игнорировать редкие, но важные события.
Oversampling полезен, когда положительный класс слишком мал. Он увеличивает представленность редких примеров и помогает модели лучше уловить закономерности.
Но важно не переусердствовать: агрессивное дублирование может привести к переобучению.
Undersampling сокращает число объектов большинства класса. Это особенно полезно, если негативных примеров слишком много и они «давят» редкий класс.
Подход хорош для быстрых экспериментов, но требует контроля: можно случайно выбросить важную структуру данных.
Во многих алгоритмах можно задать больший вес ошибкам по редкому классу. Это часто более аккуратный способ балансировки, чем механическое пересэмплирование.
Практически это помогает модели сильнее «уважать» положительный класс и лучше оптимизировать F1-score.
Одна из самых недооценённых причин низкого F1-score — использование порога 0,5 по умолчанию.
Если ваша модель выдаёт вероятности, оптимальный порог почти никогда не обязан быть равен 0,5.
Что стоит сделать:
Часто уже одно это действие даёт быстрый и дешёвый рост метрики.
Не фиксируйтесь на одном значении. В production важно понимать, как модель ведёт себя:
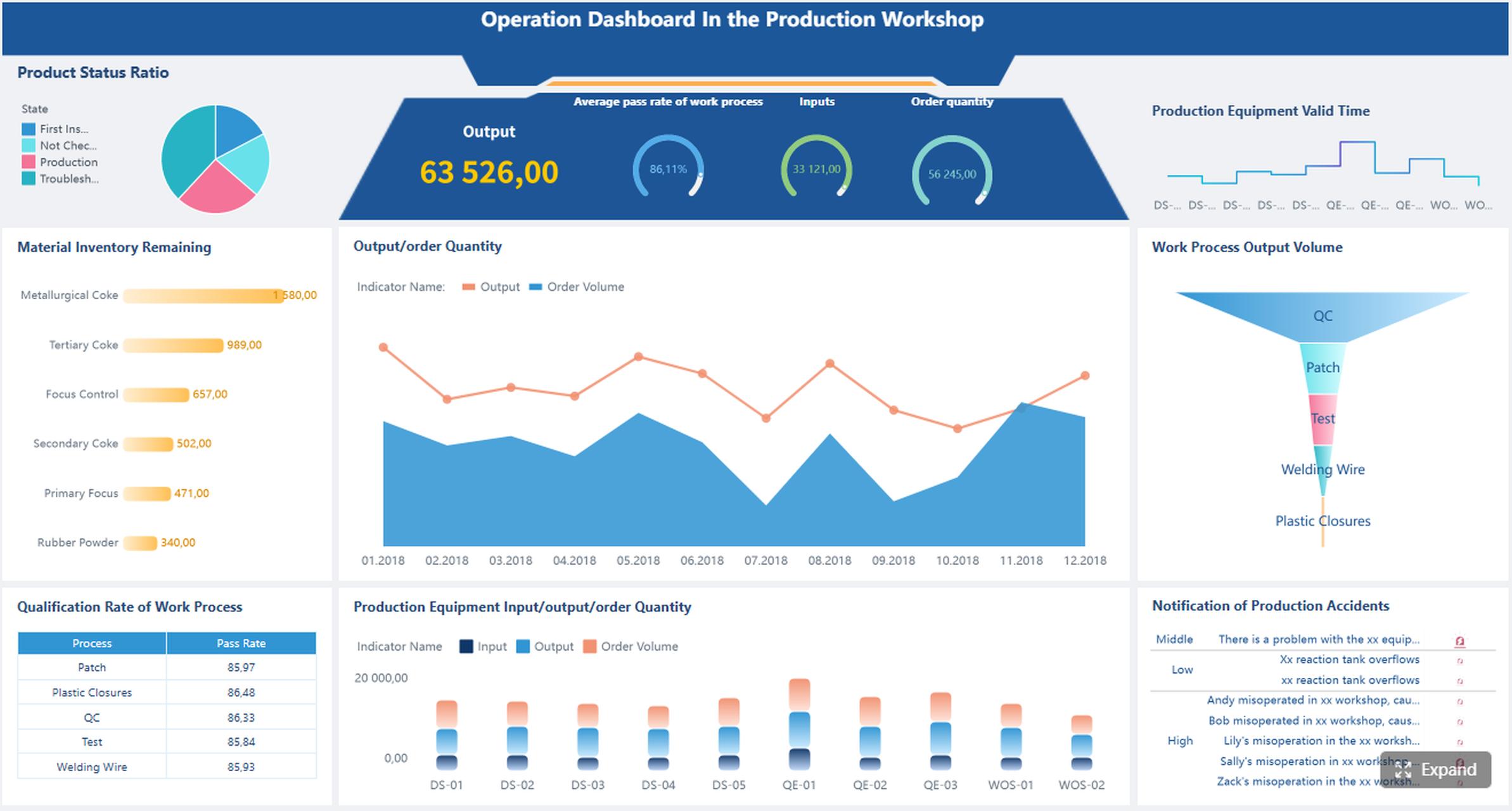
Когда базовая чистка и балансировка сделаны, следующий рычаг — feature engineering и сравнение алгоритмов.
Хорошие признаки нередко дают самый сильный прирост F1-score.
Полезные подходы:
Консультативный совет: сначала ищите признаки, которые отражают механизм события, а не просто статистическую корреляцию.
Избыточные признаки могут ухудшать обобщение, усложнять модель и вносить шум.
Особенно внимательно стоит пересматривать:
Не стоит предполагать, что первый выбранный алгоритм уже оптимален. Для F1-score часто заметную разницу дают:
Что важно на практике:
Повысить F1-score на одной выборке легко. Доказать, что модель стала лучше в реальной эксплуатации, намного сложнее.
Никогда не оценивайте улучшения по одной цифре.
Минимальный набор для сравнения экспериментов:
Например, рост F1-score может сопровождаться слишком большим числом ложноположительных срабатываний. Для бизнеса это может означать рост нагрузки на сотрудников, потери конверсии или ухудшение клиентского опыта.
Если улучшение видно только на обучающей выборке, это не улучшение, а симптом переобучения.
Проверяйте:
Здесь чаще всего теряются месяцы работы команды.
Случайное разбиение данных может серьёзно исказить выводы. Особенно это заметно на небольших или несбалансированных выборках.
Лучшие практики:
Рост F1-score сам по себе не гарантирует эффекта для бизнеса.
Проверяйте, меняется ли:
Если вам нужно быстро и без лишних итераций улучшить F1-score, двигайтесь в таком порядке:
Если коротко, ответ на вопрос «f1 score что это» звучит так: это практическая метрика, которая помогает понять, насколько модель хорошо удерживает баланс между точностью и полнотой. Она особенно полезна в задачах бинарной классификации с дисбалансом классов и высокой ценой ошибок.
Ставьте F1-score в центр внимания, если:
На практике самый быстрый эффект чаще всего дают:
Именно эти шаги обычно дают лучший результат при умеренных затратах времени.
Зрелый путь выглядит так:
Для enterprise-команд ключевая проблема редко заключается только в расчёте F1-score. Намного сложнее организовать прозрачный процесс, в котором data science, аналитика и бизнес видят одни и те же метрики, пороги, ошибки и динамику качества.
Создавать это вручную сложно; используйте FineBI, чтобы задействовать готовые шаблоны и автоматизировать весь рабочий процесс. Это особенно полезно, если вам нужно:
Когда метрики модели становятся частью регулярной управленческой аналитики, команда быстрее замечает деградацию качества, лучше понимает цену ошибок и увереннее принимает решения о дообучении, смене порога или обновлении признаков.
F1-score — это метрика, которая показывает баланс между precision и recall в задачах классификации. Она помогает понять, насколько модель одновременно хорошо находит нужные объекты и не дает слишком много ложных срабатываний.
Accuracy может выглядеть высокой даже тогда, когда модель почти не находит важный редкий класс. F1-score полезнее в таких случаях, потому что оценивает именно качество работы по положительному классу.
Эта метрика особенно полезна при несбалансированных классах и высокой цене ошибок, например в антифроде, медицине, спам-фильтрации и прогнозе оттока. Она подходит там, где важно и не пропускать нужное, и не перегружать процесс ложными тревогами.
Чаще всего F1-score улучшают настройкой порога классификации, улучшением качества данных и балансировкой классов. Также помогает подбор признаков, гиперпараметров и более подходящей модели.
Нет, F1-score лучше интерпретировать вместе с precision, recall, матрицей ошибок и бизнес-метриками. Так можно понять, какой именно тип ошибок делает модель и насколько это критично для процесса.

Автор
Yida Yin
Эксперт по отраслевым решениям FanRuan
Похожие статьи

RPA роботизация бизнес процессов: 7 способов объединить OCR и AI для автоматизации документов и заявок
Когда в компании растет поток документов, писем, анкет и заявок, ручная обработка быстро становится узким местом: сотрудники тратят часы на сортировку, перепроверку полей, перенос данных между системами и маршрутизацию о
Yida Yin
2026 июнь 11

Precision, Recall и F1: метрики классификации + мониторинг в BI
Если вы оцениваете модель классификации и видите в отчёте только «точность 95%», этого почти никогда недостаточно для решения бизнеса. Для IT руководителя, аналитика или product owner важен не общий красивый процент, а т
Yida Yin
2026 июнь 11
accuracy метрика в ML: 7 случаев, когда Accuracy хуже Precision и Recall
Если вы оцениваете классификатор только по одной цифре accuracy, вы рискуете запустить в продакшен модель, которая выглядит «хорошо» на презентации, но проваливается в реальных бизнес сценариях. Для IT менеджера это озна
Yida Yin
2026 июнь 02



