Если вы оцениваете классификатор только по одной цифре accuracy, вы рискуете запустить в продакшен модель, которая выглядит «хорошо» на презентации, но проваливается в реальных бизнес-сценариях. Для IT-менеджера это означает ложное чувство контроля, для аналитика — неверные выводы о качестве модели, для операционного директора — прямые потери из-за неправильных решений. В задачах антифрода, медицинского скрининга, скоринга, оттока и контроля качества accuracy метрика часто оказывается слишком грубой и даже опасной для интерпретации.
«Все дашборды в этой статье построены с помощью [FineBI]»
Accuracy — это доля правильных ответов модели среди всех предсказаний. В задачах классификации она отвечает на простой вопрос: какую часть объектов модель классифицировала верно.
Формально метрика считается так:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
Где:
На практике accuracy чаще всего используют:
Проблема в том, что одна высокая цифра accuracy не гарантирует, что модель полезна для бизнеса. Модель может правильно угадывать «простые» или доминирующие случаи и при этом системно ошибаться в тех объектах, которые как раз критичны для продукта.
Например, если 95% транзакций в выборке легитимны, то модель, которая почти всегда говорит «не фрод», легко покажет 95% accuracy. Но бизнесу от этого мало пользы, если оставшиеся 5% — это реальное мошенничество, которое нужно обнаружить.
Именно поэтому accuracy метрика должна читаться через матрицу ошибок, а не как самостоятельный итог качества. Матрица ошибок показывает, какие именно ошибки допускает модель, а не только их суммарную долю.
Ниже — базовый набор метрик, который нужно анализировать вместе, а не по отдельности:
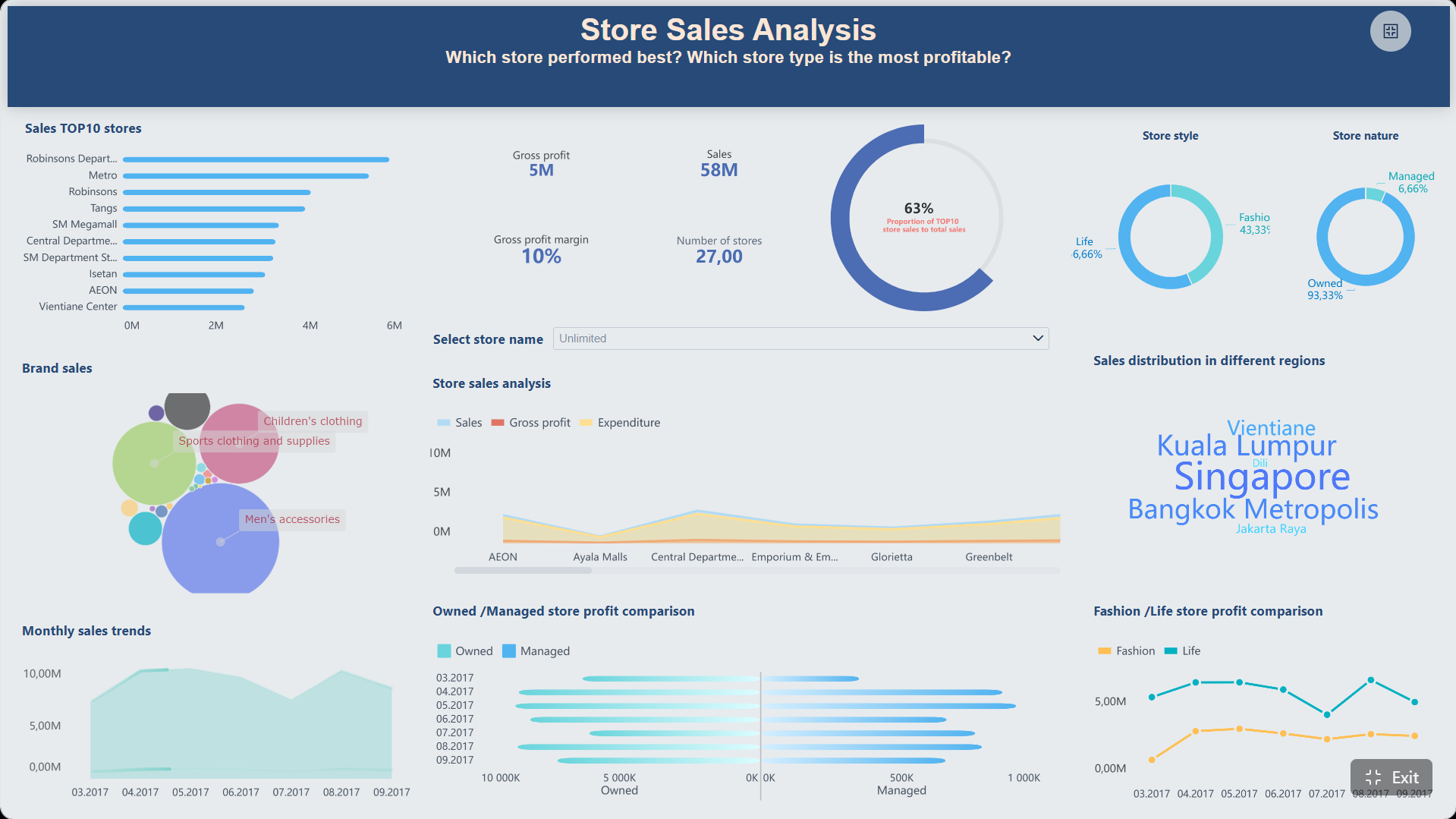
Это самый известный случай, когда accuracy метрика особенно обманчива. Если один класс сильно преобладает, модель может почти всегда предсказывать именно его и получать высокую итоговую точность.
Представим:
Если модель всегда предсказывает отрицательный класс, она получит 95% accuracy. На первый взгляд — отличный результат. Но на деле модель не нашла ни одного положительного случая.
Для бизнеса это означает следующее:
Без анализа ошибок по каждому классу вывод будет ложным. В таких задачах нужно минимум смотреть на Recall положительного класса и отдельно на Precision, если важны ложные тревоги.
Есть сценарии, где ошибочное срабатывание обходится дорого — финансово, операционно или репутационно.
Примеры:
В этих случаях приоритет смещается в сторону Precision. Вопрос звучит не так: «сколько всего ответов верно?», а так: из всех положительных сигналов сколько действительно были правильными?
Модель может иметь высокую accuracy, но если среди её положительных предсказаний слишком много ложных срабатываний, она создаёт нагрузку на команды и подрывает доверие к ML-решению.
Иногда опаснее не лишний сигнал, а пропуск нужного события.
Типовые сценарии:
Здесь ключевой вопрос: какую долю реальных положительных случаев модель смогла найти? Это и есть Recall.
Даже если общая accuracy выглядит достойно, низкий recall может означать, что модель бесполезна именно там, где нужна больше всего. В таких задачах управленческая ошибка часто возникает из-за того, что команда смотрит на среднюю «красивую» метрику и не замечает масштаб пропусков.
В реальных проектах классы редко одинаково важны. Один редкий класс может нести несоизмеримо больший риск, чем массовый.
Например:
Если просто усреднять качество через accuracy, ошибки по редкому, но важному классу «растворяются» в общей массе верных предсказаний. Поэтому метрики качества моделей бинарной классификации нужно смотреть шире:
Матрица ошибок — это основа корректной интерпретации любой классификационной модели. Она раскладывает результат на четыре типа исходов:
Одна и та же accuracy может скрывать совершенно разное поведение модели.
Например, две модели показывают 92% accuracy:
Для бизнеса это две совершенно разные модели, хотя формально accuracy одинакова. Поэтому оценка моделей двоичной классификации без матрицы ошибок почти всегда неполна.
Эти метрики отвечают на разные вопросы:
Совместный анализ даёт гораздо более полезную картину:
Для оценки моделей двоичной классификации этого минимума уже достаточно, чтобы не попасть в ловушку «красивой средней цифры».
Во многих ML-системах модель выдаёт не класс, а вероятность. Затем команда выбирает threshold — порог, после которого объект считается положительным.
И здесь возникает важный момент: небольшое изменение порога может:
То есть польза модели для бизнеса меняется заметно сильнее, чем это показывает accuracy. Если вы настраиваете систему оповещений, скоринг или детектор инцидентов, смотреть только на общую точность бессмысленно. Нужно анализировать, как threshold влияет на компромисс между ложными тревогами и пропусками.
Тестовая accuracy может выглядеть хорошо, но на реальных данных модель деградирует. Причины типичны:
Например, на тесте доля мошенничества была 10%, а в продакшене стала 1%. Модель, оптимизированная под тестовую структуру, начинает вести себя иначе. Accuracy может даже остаться «нормальной», но Precision резко упадёт, потому что ложноположительных сигналов станет непропорционально много.
Именно поэтому метрики качества работы моделей машинного обучения нужно проверять:
То, что хорошо для лидерборда, не всегда полезно для продукта. В ML-соревнованиях часто оптимизируют одну метрику ради ранга:
Но в реальном бизнесе целевая функция почти всегда шире. Например:
Поэтому при выборе метрики для ML-соревнования и прикладной задачи нельзя подменять цель. Сначала определяется бизнес-эффект ошибки, потом уже — математический критерий оптимизации.
Как консультант, я рекомендую начинать не с алгоритма и не с библиотеки, а с трёх управленческих вопросов.
1. Что опаснее для задачи: ложное срабатывание или пропуск нужного события?
Если ложное срабатывание дорого — смотрите в сторону Precision. Если критичен пропуск — приоритет у Recall.
2. Насколько сбалансированы классы и одинакова ли цена ошибок?
Если классы несбалансированы или один класс важнее другого, accuracy перестаёт быть главным ориентиром.
3. Нужна ли интерпретируемость для команды, бизнеса или заказчика?
Матрица ошибок, Precision и Recall проще объясняют поведение модели стейкхолдерам, чем абстрактная единая метрика.
Ниже — практическая схема, которой удобно пользоваться в рабочих проектах.
Можно использовать accuracy как основную метрику, если:
Нужно смещаться к Precision, если:
Нужно смещаться к Recall, если:
Нужно добавлять F1-score и анализ порога, если:
Нужно расширять набор метрик, если:
Важно и другое: не путайте выбор метрик в задачах машинного обучения для классификации и регрессии. Accuracy, Precision и Recall применимы к задачам классификации, где модель определяет класс. Для регрессии нужны другие показатели — например, MAE, RMSE, MAPE. Ошибка выбора метрики здесь ведёт к ошибке всей постановки задачи.
Ниже — 5 лучших практик, которые я советую внедрять в enterprise-проектах.
Не ограничивайтесь формулировкой «FP плохие, FN тоже плохие». Переведите ошибки в последствия:
Это позволит выбрать метрику не теоретически, а прагматично.
Смотрите не только на общий тестовый результат, но и на:
Часто именно сегментный анализ показывает, где accuracy вводит в заблуждение.
Порог 0.5 редко бывает оптимальным. Проверьте минимум 3–5 вариантов threshold и сравните:
Даже хорошая offline accuracy ничего не гарантирует после запуска. В продакшене нужно мониторить:
Руководителю недостаточно увидеть F1=0.81. Ему нужно понять:
После внедрения таких практик удобно переходить от разрозненных таблиц к управляемой визуальной системе контроля.
Accuracy метрика полезна как стартовый ориентир, но опасна как единственный критерий качества. Она хорошо работает только там, где:
Во всех остальных случаях accuracy искажает картину. Особенно в 7 сценариях, которые мы разобрали:
Практическое правило простое: сначала определите цену ошибок и структуру данных, потом выбирайте метрику. Не наоборот.
Создавать это вручную сложно; используйте FineBI, чтобы задействовать готовые шаблоны и автоматизировать весь рабочий процесс. Это особенно важно, если вам нужно регулярно сравнивать accuracy, precision, recall, матрицу ошибок, пороги и сегменты в едином управленческом контуре.
Accuracy показывает долю всех правильных предсказаний модели среди общего числа объектов. Эта метрика удобна как общий ориентир, но сама по себе не объясняет, какие именно ошибки делает модель.
При дисбалансе классов модель может почти всегда выбирать самый частый класс и все равно получать высокий показатель. В таком случае бизнес может видеть хорошую цифру, хотя важные положительные случаи модель фактически пропускает.
Precision важнее, когда ложные срабатывания обходятся дорого, например в антифроде, модерации или кредитном скоринге. Она показывает, какая доля положительных предсказаний действительно оказалась верной.
Recall критичен там, где опасно пропустить реальный положительный случай, например в медицине, кибербезопасности или предиктивном обслуживании. Он помогает понять, какую часть нужных событий модель действительно нашла.
Обычно accuracy стоит смотреть вместе с precision, recall, F1-score и матрицей ошибок. Такой набор помогает оценить не только общий уровень качества, но и цену разных типов ошибок для бизнеса.

Автор
Yida Yin
Эксперт по отраслевым решениям FanRuan
Похожие статьи

RPA роботизация бизнес процессов: 7 способов объединить OCR и AI для автоматизации документов и заявок
Когда в компании растет поток документов, писем, анкет и заявок, ручная обработка быстро становится узким местом: сотрудники тратят часы на сортировку, перепроверку полей, перенос данных между системами и маршрутизацию о
Yida Yin
2026 июнь 11

Precision, Recall и F1: метрики классификации + мониторинг в BI
Если вы оцениваете модель классификации и видите в отчёте только «точность 95%», этого почти никогда недостаточно для решения бизнеса. Для IT руководителя, аналитика или product owner важен не общий красивый процент, а т
Yida Yin
2026 июнь 11

F1 score что это и как улучшить: 10 рабочих способов поднять F1-Score модели
Когда команда внедряет модель классификации в антифрод, скоринг лидов, прогноз оттока или медицинский триаж, ошибка в выборе метрики быстро превращается в бизнес проблему. Модель может показывать «красивую» accuracy, но проваливаться там,где для бизнеса критично не пропускать важные события и не засорять процесс ложными срабатываниями.
Yida Yin
2026 июнь 03



